1 Abstract¶
The Notebook Aspect of the Rubin Science Platform is built on top of JupyterHub and JupyterLab, running inside Kubernetes. The Science Platform must spawn Kubernetes pods and associated resources for users on request, maintain internal state for which pods are running so that the user is directed to their existing pod if present, and shut down pods when requested, either by the user or the system. Spawning a pod may also require privileged setup actions, such as creating a home directory for the user.
JupyterHub provides a Kubernetes spawner that can be used for this purpose, but it requires granting extensive Kubernetes permissions directly to JupyterHub, a complex piece of software that is directly exposed to user requests. This tech note proposes an alternative design using a JupyterHub spawner that delegates all of its work to a RESTful web service, and an implementation of that web service that performs the spawning along with associated Science Platform business logic such as user home directory creation and construction of the spawner options form. This same approach can potentially be used for a custom Dask spawner for parallel computation within the Science Platform.
2 Background¶
See DMTN-164 for a complete description of the v2 architecture of the Notebook Aspect of the Rubin Science Platform. This tech note only touches on aspects relevant to pod spawning.
The v2 architecture uses JupyterHub Kubernetes Spawner to spawn user pods for notebooks, with significant local customizations via hooks defined in the nublado2 package.
Those hooks create additional Kubernetes resources used by the pod: multiple ConfigMap resources with configuration, /etc/passwd and related files for username and group mappings inside the pod; and Kubernetes secrets (via vault-secrets-operator).
Each user pod and its associated resources are created in a per-user namespace.
In addition, to support a proof-of-concept Dask integration, the initial implementation creates a ServiceAccount, Role, and RoleBinding for the user to allow them to spawn pods in their namespace.
The Kubernetes installation of JupyterHub in this architecture uses Helm and the Zero to JupyterHub Helm chart.
Configuration for the spawner is injected through the Helm chart and a custom ConfigMap resource.
The list of resources to create in each user namespace when spawning is specified in the Helm configuration as Jinja templates, which are processed during spawn by the custom spawn hooks.
This system is supported by two ancillary web services. moneypenny is called before each pod spawn to provision the user if necessary. Currently, the only thing that it does is create user home directories in deployments where this must be done before the first spawn. This design is described in SQR-052.
Second, since the images used for user notebook pods are quite large, we prepull those images to each node in the Kubernetes cluster. This is done by cachemachine. The cachemachine web service is also responsible for determining the current recommended lab image and decoding the available image tags into a human-readable form for display in the spawner menu.
2.1 Problems¶
We’ve encountered several problems with this approach over the past year.
The current Dask proof-of-concept grants the user creation permissions in Kubernetes to spawn pods. Since pod security policies are not implemented on Science Platform deployments, this allows users to spawn privileged pods and mount arbitrary file systems, thus bypassing security permissions in the cluster and potentially compromising the security of the cluster itself via a privileged pod.
Allowing JupyterHub itself to spawn the pods requires granting extensive Kubernetes permissions to JupyterHub, including full access to create and execute arbitrary code inside pods, full access to secrets, and full access to roles and role bindings. Worse, because each user is isolated in their own namespace, JupyterHub has to have those permissions globally for the entire Kubernetes cluster. While JupyterHub itself is a privileged component of the Science Platform, it’s a complex, user-facing component and good privilege isolation practices argue against granting it that broad of permissions. A compromise of JupyterHub currently means a complete compromise of the Kubernetes cluster and all of its secrets.
Creation of the additional Kubernetes resources via hooks is complex and has been error-prone. We’ve had multiple problems with race conditions where not all resources have been fully created (particularly the
Secretcorresponding to aVaultSecretand the token for the user’sServiceAccount) before the pod is spawned, resulting in confusing error messages and sometimes spawn failures. The current approach also requires configuring the full list of resources to create in the values file for the Notebook Aspect service, which is awkward to maintain and override for different environments.JupyterHub sometimes does a poor job of tracking the state of user pods and has had intermittent problems starting them and shutting them down cleanly. These are hard to debug or remedy because the code is running inside hooks inside the kubespawner add-on in the complex JupyterHub application.
The interrelated roles of the nublado2, moneypenny, and cachemachine Kubernetes services in the spawning process is somewhat muddled and complex, and has led to problems debugging service issues. nublado2 problems sometimes turn out to be cachemachine problems or moneypenny problems but it’s not obvious that this is the case from the symptoms or logs.
We have other cases where we would like to spawn pods in the Kubernetes environment with similar mounts and storage configuration to Notebook Aspect pods but without JuptyerHub integration, such as for privileged administrator actions in the cluster. Currently, we have to spawn these pods manually because the JupyterHub spawning mechanism cannot be used independently of JupyterHub.
3 Proposed design¶
The proposed replacement design moves pod spawning into a separate web service and replaces the spawner implementation in JupyterHub with a thin client for that web service. The spawner service would subsume cachemachine and moneypenny and thus take over responsibility for prepulling images, constructing the spawner options form based on knowledge of the available images, and performing any provisioning required for the user before starting their lab.
The spawner service API would also be available for non-JupyterHub spawning, including Dask. This would replace the Kubernetes spawning code in Dask Kubernetes.
As a result of those changes, all Kubernetes cluster permissions can be removed from both JupyterHub and the spawned user pods. Instead, both JupyterHub and user pods (via Dask) would make requests to the spawner service, authenticated with either JupyterHub’s bot user credentials or the user’s notebook token. That authentication would be done via the normal Science Platform authentication and authorization system (see DMTN-234). The spawner service can then impose any necessary restrictions, checks, and verification required to ensure that only safe and expected spawning operations are allowed.
Only the spawner service itself will have permissions on the Kubernetes cluster. It will be smaller, simpler code audited by Rubin Observatory with a very limited API exposed to users.
Inside JupyterHub, we would replace the KubeSpawner class with an APISpawner class whose implementation of all of the spawner methods is to make a web service call to the spawner service.
We can use the user’s own credentials to authenticate the spawn call to the spawner service, which ensures that a compromised JupyterHub cannot spawn pods as arbitrary users.
Other calls can be authenticated with JupyterHub’s own token, since they may not be associated with a user request.
The spawner service will know which user it is spawning a pod for, and will have access to the user’s metadata, so it can set quotas, limit images, set environment variables, and take other actions based on the user and Science Platform business logic without having to embed all of that logic into JupyterHub hooks.
Here is that architecture in diagram form.
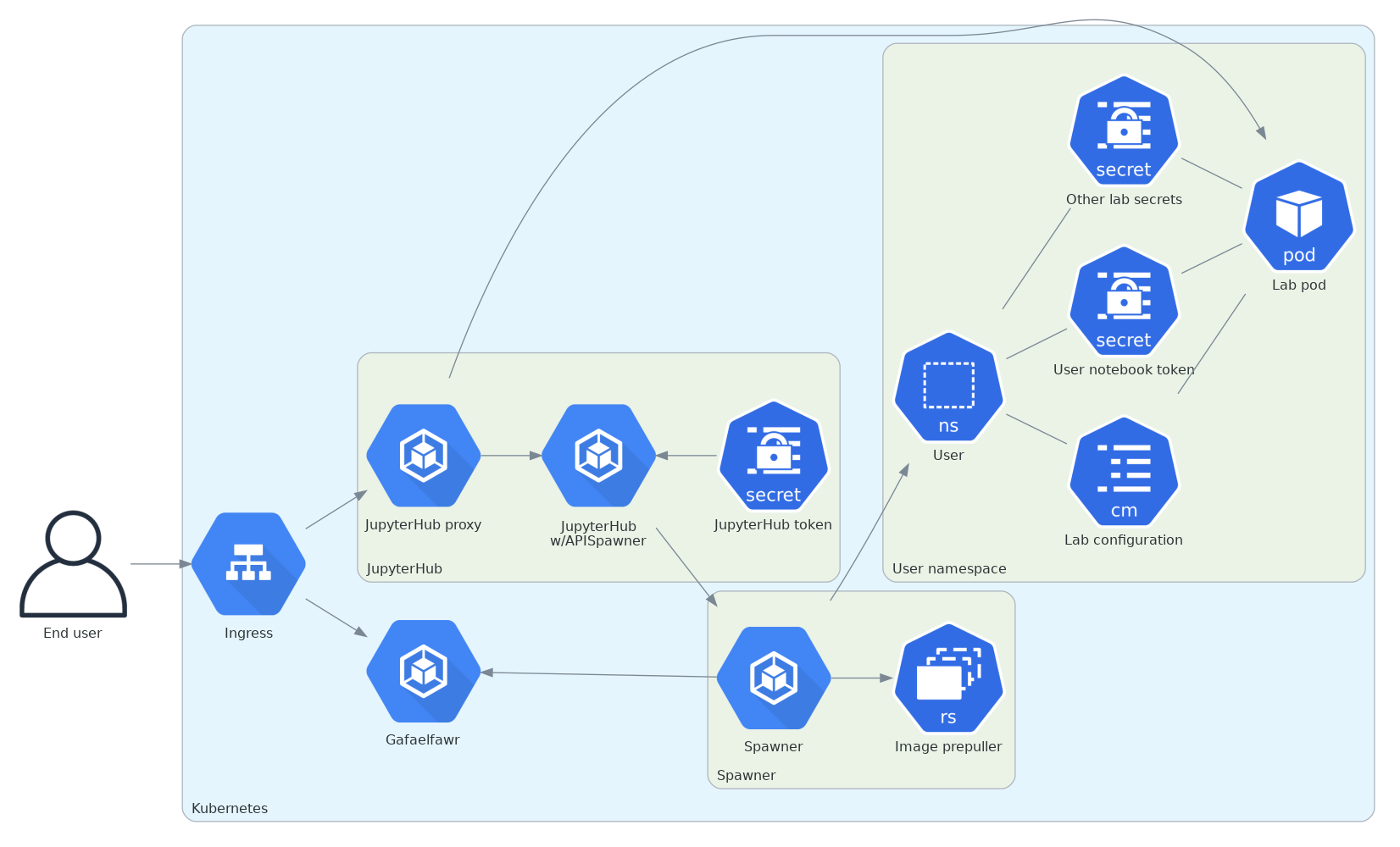
Figure 1 High-level structure of the JupyterHub architecture using an external spawner. This diagram is somewhat simplified for clarity. The lab may also talk to the spawner to spawn Dask pods, JupyterHub and the lab talk over the internal JupyterHub protocol, and both JupyterHub and the lab talk to the spawner via the ingress rather than directly.¶